Note 7 File Organization
Author: Zhen Tong Lecturer: Jane YOU
In this note, we will introduce how the database is built physically, which is a more engineering question than before. This is the essence part in this subject. Let’s get started!
file organization
How is the database stored in your computer?
- One Database → Multiple Files:
- This suggests that a database is not confined to a single file but can be distributed across multiple files. This approach can be useful for managing large amounts of data or for organizing data based on different criteria.
- One File → Sequence of Records:
- Each file in the database contains a sequence of records. In the context of databases, a record typically represents a collection of related data items.
- A Record → Sequence of Fields:
- A record is further broken down into a sequence of fields. Each field represents a specific attribute or piece of information about the entity described by the record.
- File → Fixed-Length Storage Units (Blocks):
- The file is composed of fixed-length storage units called blocks. These blocks are used to store records and provide a convenient way to manage and access data efficiently.
Fixed-Length record
Have you ever concerned about why the SQL code needs to define the length of your data domain space? For example:
Creating a file with instructor records:
type instructor = record
ID varchar(5);
name varchar(20);
dept_name varchar(20);
salary numeric(8,2);
endOne record corresponds to one tuple.
The size of one instructor record is (5 + 20 + 20 + 8 = 53) bytes.
In a block, we allocate the maximum number of records it can contain.
Since insertions are more frequent than deletions, space occupied by deleted records is kept empty until later insert operations reuse this space.
At the beginning of the file, specific bytes are allocated as the file header, forming a free list (a linked-list data structure).
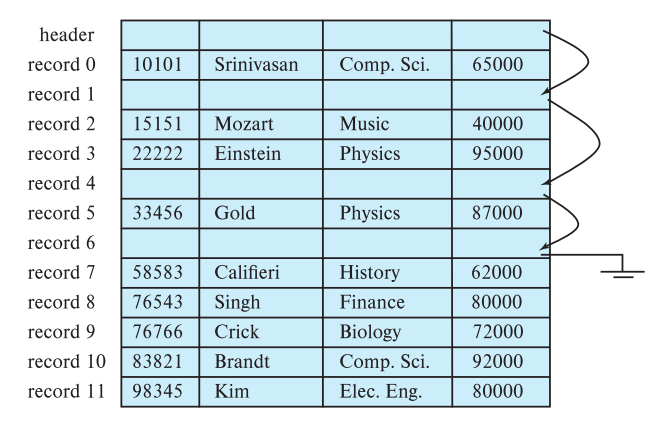
- When inserting,
list.pop()is used.
- When deleting,
list.add()is used.
- When
list.is_empty == true, insertion occurs at the end of the file.
Variable-Length Records
There are 2 questions we need to solve:
- How to design the protocol (or structure) of a single record so that it can have variable length.
- How to store variable-length records in a block so that the records in a block can be easily extracted.
Records with variable-length attributes consist of two parts:
- An initial part with fixed-length information.
- Immediately following is the content of variable-length attributes, represented in the initial part as an array of (offset, length).
Assuming an instructor's record where the first three attributes (ID, name, and dept_name) are variable-length strings, and the fourth attribute (salary) is a fixed-size numeric:
Offset and length are stored in 2 bytes each, and the initial part for each variable-length attribute occupies 4 bytes.
0-3, 4-7, 8-11, 12-19
The salary attribute occupies 8 bytes.
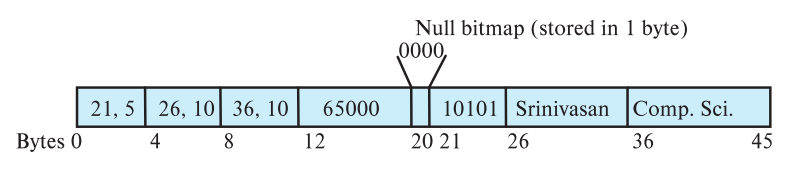
A four-bit NULL bitmap is used to indicate which positions are empty. Since there are 4 attributes, there are 4 null bits.
Organization of Records in Files
After we know how to represent a record, our next question is how to organize them. Using what kinds of data structure?
Heap file
When a record is created, it stays in a certain space on the disk. We seldom change its location, because changing the physical location for it is time-consuming (If you learned Operating System, the Disk is the lowest layer of your memory, which means it costs you a lot to lift it from the bottom)
Free-space map: A data structure (array) used to save space
Every block is assigned a value that shows the free space remaining in one block. Free space is space not occupied by data,
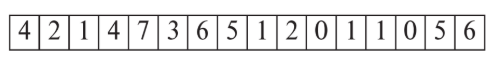
2 means 2/8 of the space is free.
To store a new record, go to the array and find a suitable space. If it doesn't exist, assign it a new block. This approach is faster than a direct traversal lookup, but still not fast enough
Establishing a Two-Level Free Map: For example, where each element represents the maximum free space within 100 entries of the first-level free-space map.
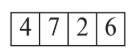
In an exceptionally large relational graph, the first search time is reduced to 1/100, and the second search range is 100.
The cost of reducing search expenses is an increased cost of establishing the two-level free map. As a result, the establishment of the two-level free map is periodically written (rather than immediately updated), leading to potential outdated errors in the two-level free map.
Sequential File Organization
Efficient handling of search keys (which can be any attribute or set of attributes) is achieved by organizing them in a linked list in sequential order (to minimize the number of block accesses in sequential file processing).
The benefit of sequential ordering is the ability to perform binary search (O(log N)).
Insert Operation:
- Locate the record before the point of insertion.
- Placement:
- If the block containing this record has space for at least one free record, insert this new record.
- Otherwise, insert the new record into an overflow block.
- Adjust the connections of pointers.
Drawback: While initially fast due to physically adjacent blocks and sequentially ordered records, the efficiency of sequential processing decreases as the number of overflow blocks increases. The similarity between search keys and physical blocks diminishes, necessitating a file reorganization based on the existing order, which comes with a high cost.
Multitable Clustering File Organization
In a single block, more than one relation's records are stored.
Calculating the relationship between the "department" and "instructor" relations:
sqlCopy code
SELECT dept_name, building, budget, ID, name, salary
FROM department NATURAL JOIN instructor
For each tuple in the "department" relation, the system must find instructor tuples with the same dept_name value.
In the worst case, each instructor record is stored in a different block → every time a required record is sought, a block read operation must be executed.
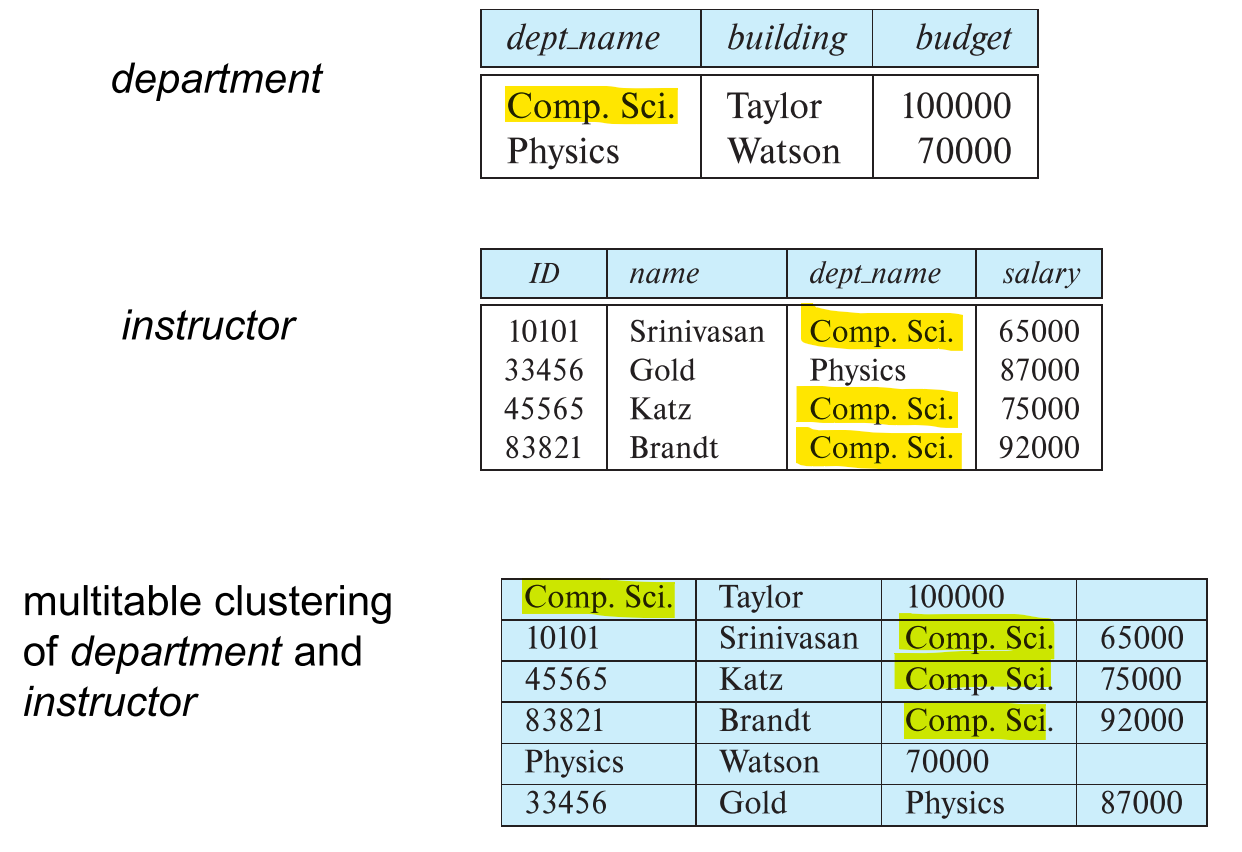
Multitable Clustering Definition:
All relation tuples pertaining to a specific A_B cluster are output near the corresponding to A_B. We say that relations A and B are clustered on the A_B key.
Cluster Key:
An attribute that defines which records are stored together, such as dept_name in the example.
Advantages: Accelerates specific join queries.
Disadvantages: Other operations may become slower.
Partitioning
In a table (relation), records (tuples) can be divided into smaller relations. This kind of table partitioning is often based on the values of an attribute.
For example, partitioning the "transaction" relation by year:
sqlCopy code
SELECT *
FROM transaction
WHERE year = 2019
After partitioning, only the transaction_2019 relation will be accessed.
Advantages:
- Reducing the size of the table (relation) can decrease the time cost of operations, such as finding free space.
- Different partitioned relations can be stored on different disks, based on access frequency.
Data Dictionary Storage
Metadata: Data about data. For example, data about relations (tables): the schemas of relations.
Metadata is stored in the Data Dictionary (system catalog).
Information that needs to be stored includes:
Relation-related:
- Names of relations
- Names of attributes for each relation
- Domain and length of attributes
- Names and definitions of views
- Integrity constraints
User-related:
- User names, passwords, permissions
Physical-related:
- Storage organization (heap, sequential, hash...)
- Physical location of relations
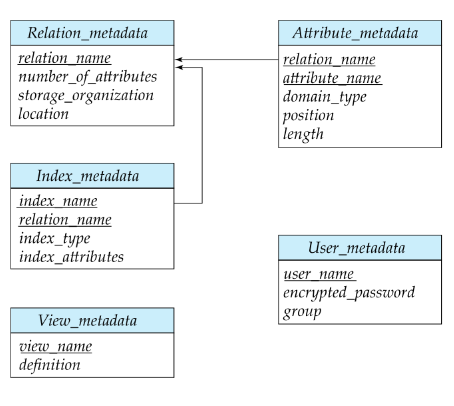
Metadata is used to maintain data about relational data.
6. Data Buffering
Buffer Concept
The data in a database primarily resides on disks.
→ Accessing data on disks is slower than accessing data in memory.
→ Aim to minimize the number of blocks transferred between disk and memory.
→ Reduce the number of disk access times.
→ Keep as many blocks as possible in main memory.
→ Maximize the probability that the required blocks are already in main memory ← Keeping all blocks in main memory is impossible.
Buffer: An area in main memory used to store copies of disk blocks. The Buffer Manager is the system that allocates buffer space.
Double buffering
Double buffering can be used to read continuous stream of blocks Use of two buffers, A and B, for reading from disk (More than 2 buffers can be used)
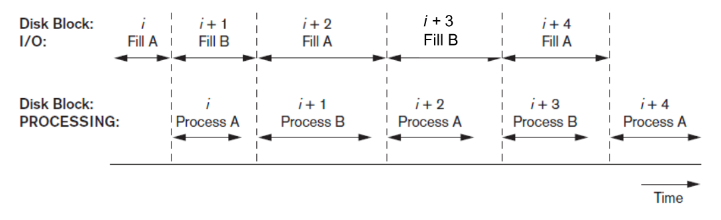
Buffer
Buffer Manager
When a disk block needs to be accessed (pseudocode):
if (block in buffer){
return block address to caller
}
else{
select a buffer that has been changed and write it back to the disk
then replace its position with the target block
return block address to caller
}Buffer Replacement Strategies (Evicted):
- Least Recently Used (LRU)
- First in First Out (FIFO)
- Most Recently Used (MRU)
Pinned Block被钉住的块
When a block is read from the buffer, if it is moved out by another process or is being written out while being removed from the buffer, problems may arise.
Pin: A pinned block will not be moved out under any circumstances.
Unpin: Used to release the pin after the read operation is completed.
Shared and exclusive locks on buffer 共享排他锁
When adding or removing tuples, no other processes should perform read operations.
- Only one process can obtain an exclusive lock at a time.
- When a process holds an exclusive lock, other processes cannot execute shared locks on the same block.
- Exclusive locks can only be granted to processes one at a time.
- A block with a shared lock cannot be held simultaneously with an exclusive lock.
- If a process applies for an exclusive lock while holding a shared lock, it will not be immediately granted but will be in a waiting state.
- Multiple processes can be concurrently given shared locks.
- If a process applies for a shared lock on a block, and no other processes hold an exclusive lock on that block, then the shared lock can be granted.
- Otherwise, the shared lock can be granted only after the exclusive lock is released.
- Only one process can obtain an exclusive lock at a time.
Buffer-Replacement Policies 替换策略
A database system can predict future access patterns more accurately than an operating system.
By examining each step required to perform user-requested operations, the database system can anticipate in advance which blocks will be needed.
Toss-immediate strategy 立即丢弃策略
Once the last tuple in a block of a relation file has been processed, the buffer manager should be instructed to free up the space occupied by this block.
Perform a natural join operation and output all attributes.
SELECT * FROM instructor NATURAL JOIN department;Pseudocode:
for each tuple i of instructor do for each tuple d of department do if i[dept name]= d[dept name] then begin let x be a tuple defined as follows: x[ID]:= i[ID] x[dept name]:= i[dept name] x[name]:= i[name] x[salary]:= i[salary] x[building]:= d[building] x[budget]:= d[budget] include tuple x as part of result of instructor ⋈ department end end endOnce a block consisting of several elements in the instructor is processed, this block no longer needs to be stored in the main memory.
Most recently used (MRU) 最近最经常使用策略
Consider the department in the example above. When the for loop is processing a , it is pinned.
Once the for loop completes processing a $department_i$, this tuple will not appear in the subsequent for loops, so it is marked as Most Recently Used (MRU). It can be removed after unpinning.
Column-Oriented Storage列式存储
- Column-Oriented Storage
Store each attribute of the relation separately.
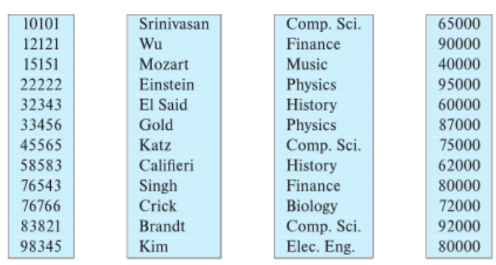
Advantages:
- Reduces I/O if only a few attributes are accessed.
- Improves CPU cache performance.
- Enhances compression performance.
- Modern CPU architectures with vector processing allow CPU operations to be applied in parallel to multiple elements of an array (e.g., comparing an attribute to a constant).
Disadvantages:
- Cost of reconstructing tuples from columnar representation.
- Cost of tuple deletion and updates.
- Cost of decompression.
Columnar representation is often more effective in decision support than row-oriented representation.
Some databases support both representations, known as row/column mixed storage.
- Column-Oriented Storage
Chapter 11.b Indexing
Conception
motivation: If you want to search for a single data (or a part of data), then searching a whole table is not cost-efficient.
For example, if you want to search a record for a student given an ID, the process is:
- The database system parses the instruction into searching execution.
- Search for the index
- Find the block, and read data from it.
Drawbacks of a large database index:
- Enormous Index Size
- Search times still remain long
- Index changes due to data additions or deletions
Search Key: A set of attributes designated for locating records in a file. The search key points to the target record.

Index: A file consisting of records (called index entries) derived from a table.
- Order Index:
Ordered based on the values.
- Hash Index
Index Evaluation Metrics
access type:Includes records where specific attribute values can be found
access time:The time when the access operation was performed
insertion / deletion time: Time to insert (delete) data. Including the time to find data and update the lead
space overhead: Space overhead, the extra space taken up by the cable.
顺序引索 ordered indexing
Storing the values of the search key in the order of the sorted search codes.
Primary Index: The order specified by the search code is the same as the order of the file (the search key does not necessarily have to be the search code).

Secondary Index: An index where the order specified by the search code is different from the order of the file. The key values may be unique or not unique.

Indexed-sequential file:Assume that all files are stored according to a search code
稠密、稀疏索引Dense/Sparse Index Files
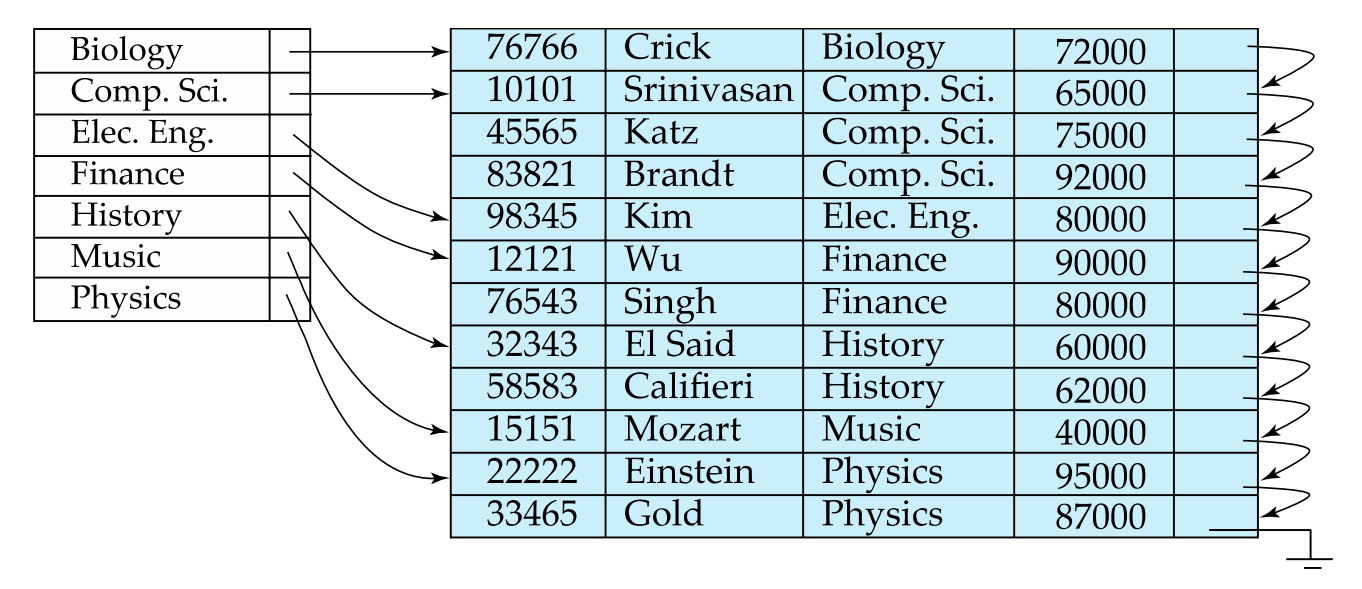
Dense index
Dense index: Every search key corresponds to a pointer index entry. Records with the same search code value are sequentially pointed to after the first record.
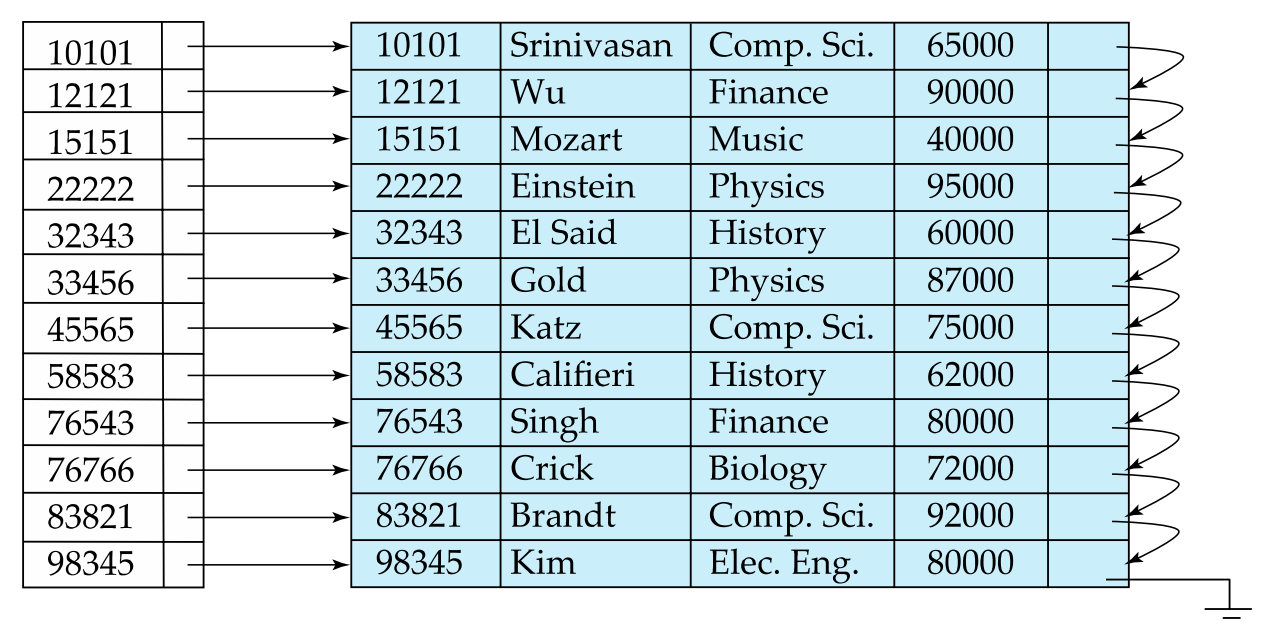
Here is an example where the search key is not the primary key (dept_name).
Note that the file must be sorted in the order of the search key, or else it will not be a cluster index.
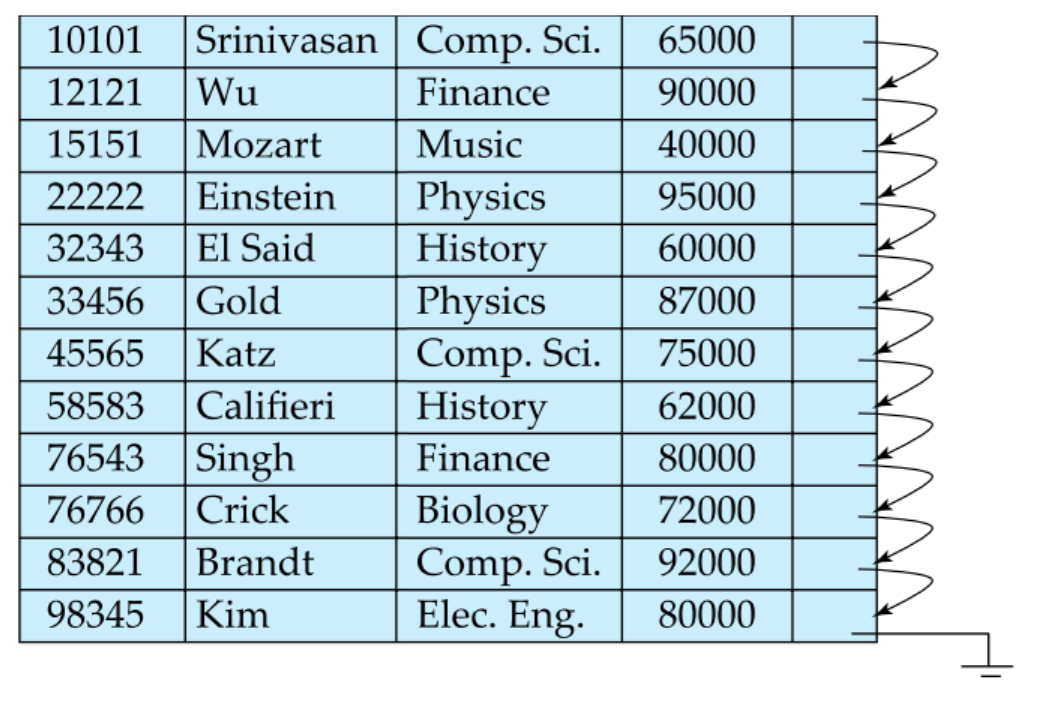
Sparse Index
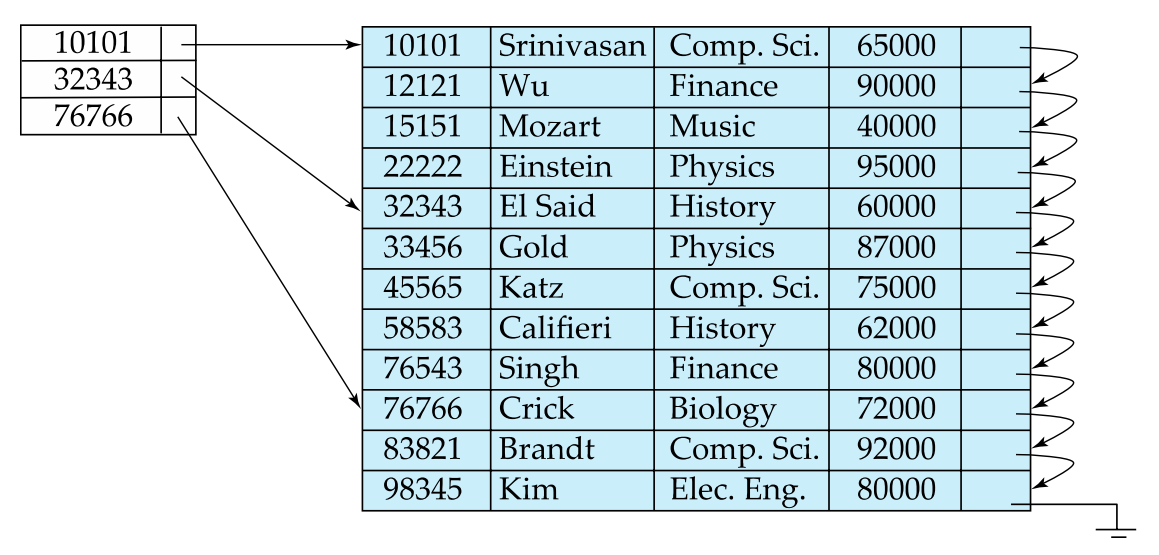
Sparse index is established only for certain search keys, but the first record pointed to will sequentially link the remaining records.
In other words, sparse index is only used when creating a cluster index.
Pros and Cons
dense index: Shorter Searching time
sparse index: Smaller space costing, space overhead small
辅助索引Secondary Index
A Secondary Index must be dense.
For every value of a search key, there is an index entry, and there is a pointer for any record in the file.

In contrast, a cluster index can be sparse. Even if only a portion of the search key values is stored, we can sequentially access records of this category and find the target records due to the rigor of the structure.
The similarity between Secondary Index and dense index is that each value of the search key has a record as a search object, but the records in the index are in disorder.
If the secondary index does not point to a candidate key, it is not feasible to point to only the first search record like a cluster index (fundamental difference). This is because records with other search codes may exist throughout the file.
Therefore, a secondary index must include pointers for all search records.
与之相对的是cluster index可以是稀疏的。即使只存储部分的搜索码的值但是通过结构的严谨性我们可以顺序访问这个类目标的记录找到目标的记录。 Secondary Index 的样子与稠密引索的相同点就是每一个搜索键的值都有一个记录作为搜索对象但是引索中的记录是乱序排列的。 如果secondary index指向的不是候选码,那么像cluster index 一样只指向第一个搜索记录s1不可行的(本质区别)。这是因为拥有其他搜索码的记录会存在在整个文件的各个地方。 因此辅助引索必须包括所有的搜索记录的指针。
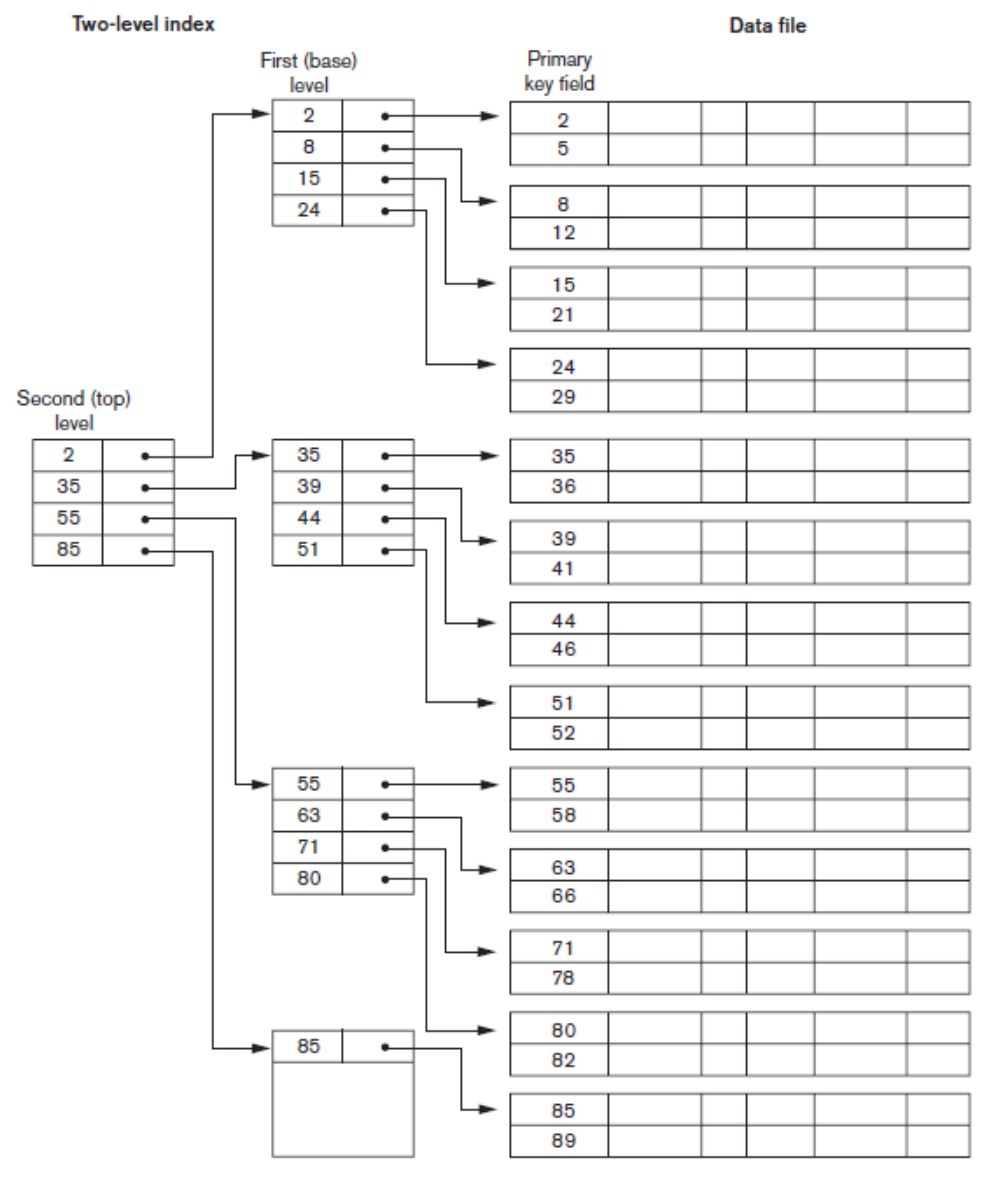
多级索引
When the index grows beyond the capacity of the main memory, arrange the original index in order and build a sparse outer index on top of the original index. Because the inner index is ordered, the outer index can be sparse.
Binary search on the outer index → Binary search on the inner index pointer → Scan and traverse the specified linked list (block).
当引索达到不能放进主存的时候,将原始引索顺序排列并在原始引索之上构建一个稀疏的外层索引。因为内层引索是顺序排列的所以外层索引是稀疏可以成立。 二分查找外层索引→内层二分查找指针→扫描遍历指定的链表(块)